用户变量
可以先在用户变量中保存值留待以后引用,可以将值从一个语句中传递到另一个语句;用户变量和连接有关,所以客户端连接断开后自动销毁。
用户变量的形式为@var_name,其中变量名var_name可以由当前字符集的文字数字字符、‘.’、‘_’和‘$’组成。 默认字符集是cp1252 (Latin1)。可以用mysqld的–default-character-set选项更改字符集。参见5.10.1节,“数据和排序用字符集”。用户变量名对大小写不敏感。
默认值
没有初始化的用户变量默认为 NULL
如果用户变量分配了一个字符串值,其字符集和校对规则与该字符串的相同。用户变量的可压缩性(coercibility)是隐含的。(即为表列值的相同的可压缩性(coercibility)。
设置用户变量方法
设置用户变量方法1
设置用户变量的一个途径是执行SET语句:
SET @var_name = expr [, @var_name = expr] ...
对于SET,可以使用=或:=作为分配符。分配给每个变量的expr可以为整数、实数、字符串或者NULL值。
设置用户变量方法2
也可以用语句代替SET来为用户变量分配一个值。在这种情况下,分配符必须为:=而不能用=,因为在非SET语句中=被视为一个比较 操作符:
mysql> SET @t1=0, @t2=0, @t3=0;
mysql> SELECT @t1:=(@t2:=1)+@t3:=4,@t1,@t2,@t3;
+----------------------+------+------+------+
| @t1:=(@t2:=1)+@t3:=4 | @t1 | @t2 | @t3 |
+----------------------+------+------+------+
| 5 | 5 | 1 | 4 |
+----------------------+------+------+------+
用户变量的表达式用法
用户变量可用在表达式中。目前不包括明显需要文字值的上下文中,例如SELECT语句的LIMIT子句,或者LOAD DATA语句的IGNORE number LINES子句。
注释:在SELECT语句中,表达式在发送到客户端后才计算,这说明在HAVING,GROUP BY,ORDER BY 字句中,不能使用包含SELECT列表中所设的变量的表达式。
例如,下面的语句不能按期望工作:
mysql> SELECT (@aa:=id) AS a,(@aa+3) AS b FROM table HAVING b=5;
HAVING子句中引用了SELECT列表中的表达式的别名,使用@aa。不能按期望工作:@aa不包含当前行的值,而是前面所选的行的id值。
一般原则是不要在语句的一个部分为用户变量分配一个值而在同一语句的其它部分使用该变量。可能会得到期望的结果,但不能保证。
设置变量并在同一语句中使用它的另一个问题是变量的默认结果的类型取决于语句前面的变量类型。
下面的例子说明了该点:
mysql> SET @a='test';
mysql> SELECT @a,(@a:=20) FROM tbl_name;
对于该 SELECT语句,MySQL向客户端报告第1列是一个字符串,并且将@a的所有访问转换为字符串,即使@a在第2行中设置为一个数字。执行完SELECT语句后,@a被视为下一语句的一个数字。
要想避免这种问题,要么不在同一个语句中设置并使用相同的变量,要么在使用前将变量设置为0、0.0或者”以定义其类型。
未分配的变量有一个值NULL,类型为字符串
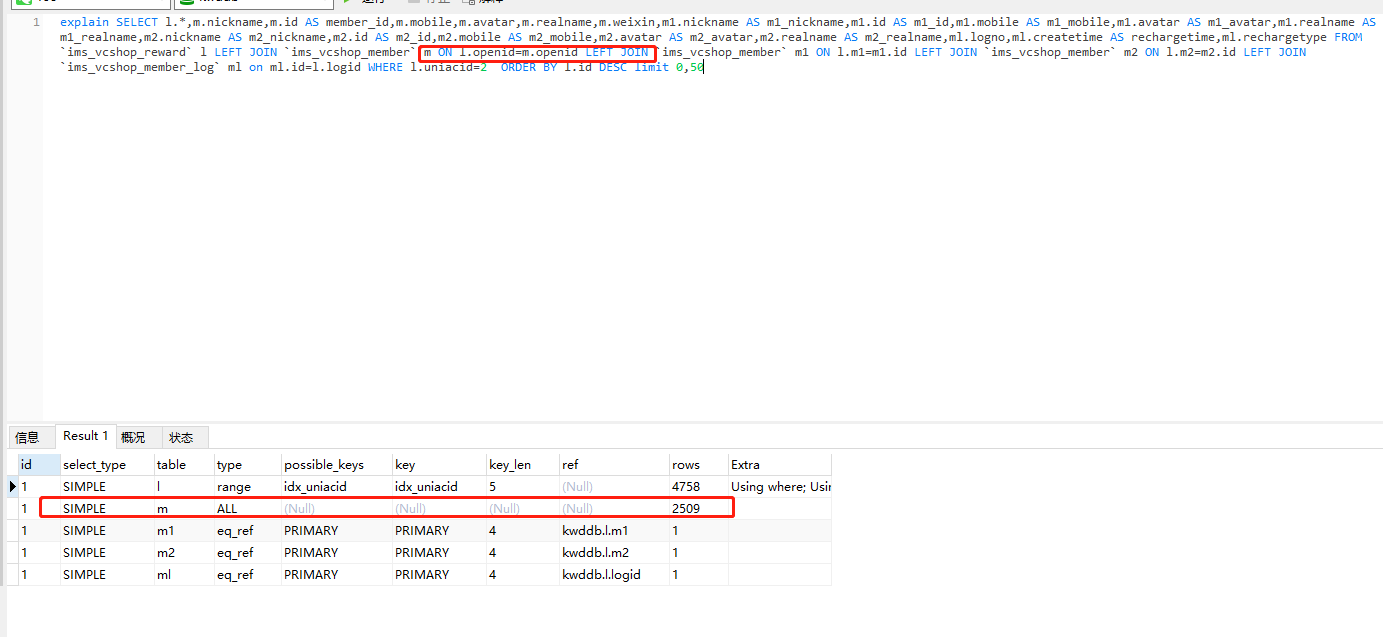
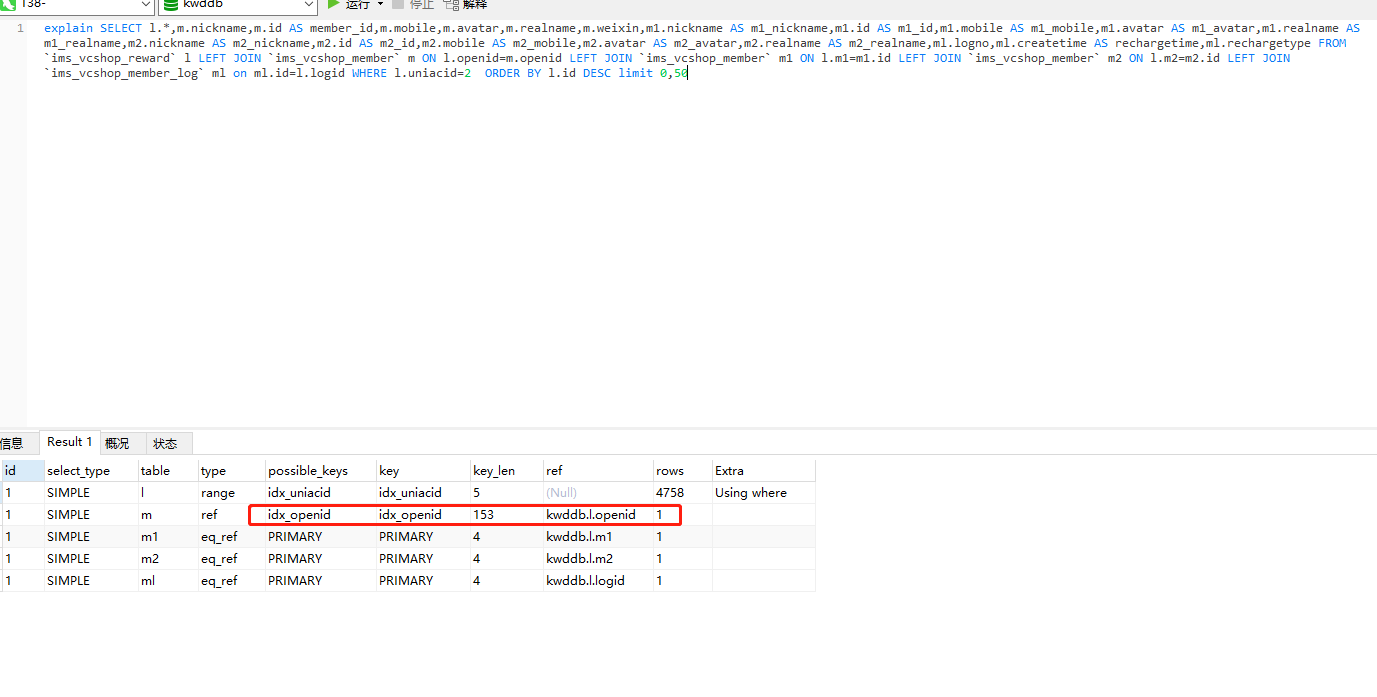
用户变量实践:
编写一个 SQL 查询,查找所有至少连续出现三次的数字。
+----+-----+
| Id | Num |
+----+-----+
| 1 | 1 |
| 2 | 1 |
| 3 | 1 |
| 4 | 2 |
| 5 | 1 |
| 6 | 2 |
| 7 | 2 |
+----+-----+
例如,给定上面的 Logs 表, 1 是唯一连续出现至少三次的数字。
+-----------------+
| ConsecutiveNums |
+-----------------+
| 1 |
+-----------------+
来源:力扣(LeetCode)
链接:https://leetcode-cn.com/problems/consecutive-numbers
著作权归领扣网络所有。商业转载请联系官方授权,非商业转载请注明出处。
题解:
#方法1
#连续出现的意味着相同数字的 Id 是连着的,由于这题问的是至少连续出现
#3 次,我们使用 Logs 并检查是否有 3 个连续的相同数字。
#并添加关键字 DISTINCT ,去除重复元素。
SELECT DISTINCT
l1.Num AS ConsecutiveNums
FROM
Logs l1,
Logs l2,
Logs l3
WHERE
l1.Id = l2.Id - 1
AND l2.Id = l3.Id - 1
AND l1.Num = l2.Num
AND l2.Num = l3.Num
#但是以上方法存在一个问题就是,当数据出现物理删除导致ID不连贯的时候会出现异常
#方法2
#使用用户变量,用cnt和pre两个变量来统计
select DISTINCT a.Num ConsecutiveNums from (
select t.Num,
@cnt:=IF(@pre=t.Num,@cnt+1,1) cnt,
@pre:=t.Num pre
from Logs t,(select @cnt:=0,@pre:=NULL) b ORDER BY t.Id asc) a
where a.cnt>=3
#满足题意,并解决了数据物理删后ID不连续的问题